많은 기업이 알고리즘 문제들을 개발자 인터뷰로 사용하곤 한다. 실전 개발에서 인터뷰 수준의 알고리즘을 다룰 일이 별로 없다는 점에서 논쟁거리가 되곤 하지만, 더 좋은 인터뷰 형식을 만드는 것도 어려운 문제라서 어쩔 수 없는 차선책으로 받아들여지는 듯하다. 그렇다면 알고리즘 대회는 실전 개발과 전혀 상관이 없을까? 이 글에서는 실전에서 의미가 있었던 드문 (?) 사례를 적어본다.
대회 문제 🔗
알고리즘 대회의 많은 문제 중, 묘하게 가장 기억에 남는 문제는 2005년 베이징
대학생 대회 예선 문제 중 하나인 Purifying
Machine이었다 (직접 출전한 것도 아니다). 간단하게
설명하자면, 2^N개의 치즈 중에 M개의 치즈가 오염되었을 때 (1 ≤ N ≤ 10, 1 ≤ M ≤ 1000), 이 오염된 치즈를 모두 정제하기 위한 최소한의 작업 수를 찾는 문제였다.
한 번의 정제로 최대 두 개의 치즈를 처리할 수 있는데, 단 이 치즈들 번호가 2진수로
표현했을 때 하나만 차이가 나야 한다. 예를 들어, 56번 치즈(0111000)와 120번
치즈는 (1111000) 같이 처리할 수 있지만, 1번과 (01) 2번은 (10)은 같이 할 수
없다. 만약 1, 3, 4, 5번 치즈가 오염 되었다면, 1과 5를 한 번에, 그리고 3과 4를 한
번에 처리함으로써 총 두 번 만에 모든 치즈를 처리할 수 있다.
⚠️ 스포일러 주의: 다음 문단에 답이 있습니다.
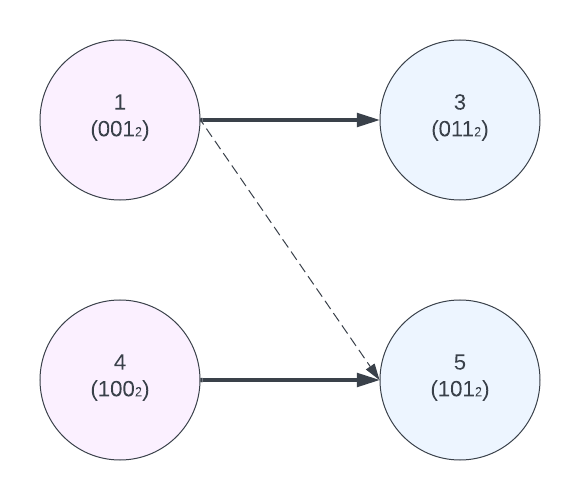
이 문제를 두고 고민을 오래 했는데, 결국 다른 친구에게 물어봐서 답을 이해했다. 이 문제의 핵심은 일렬로 적힌 치즈 숫자들을 이분 그래프(bipartite graph)로 구조화하는 데 있다. 이진수로 표현했을 때, 1의 개수가 홀수인 수들은 왼쪽에, 아닌 수들은 오른쪽에 두고, 같이 처리될 수 있는 수들을 선으로 이으면 이 혼란스러운 문제가 유명한 최대 이분 매칭 (Maximum Bipartite Matching) 문제가 되고, 효율적으로 계산이 가능해진다. 한 번의 정제 작업으로 최대 두 개의 치즈만 해결할 수 있기 때문에, 최대 매칭을 하고 나머지 치즈는 하나씩 해결하는 것이 곧바로 답이 된다. 이처럼 문제 해결의 핵심은 다양한 각도에서 문제를 두들겨보고 변형하여, 풀만한 구조를 찾는 데 있다.
업계 배경 지식: 클러스터 운영 (Cluster Management) 🔗
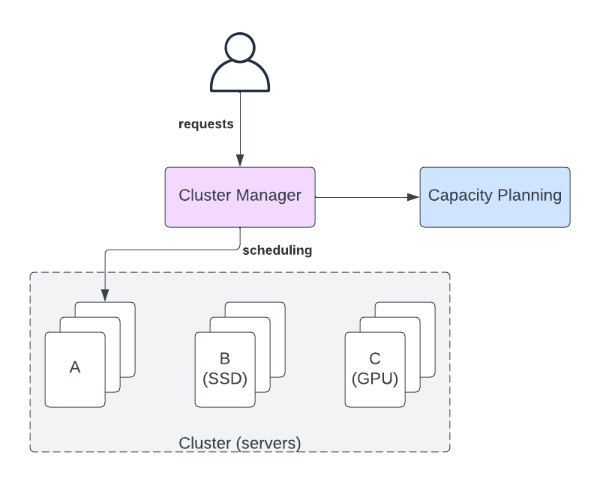
이제 업계에서 널리 쓰고 있는 쿠버네티스(k8s) 같은 클러스터 운영 시스템에 대해서 생각해보자. k8s가 성공한 원인은 그 위 레이어의 서비스 개발자들이 아래의 기반 인프라에 대한 고민을 줄이고, 요청 사항에 집중할 수 있게 분리를 해준 데 있다. 예를 들어, 내가 맡은 서비스는 vCPU = 2, 메모리 = 8GiB를 소비하는 프로세스가 10개 필요하다고 요청하는 식이다. 이전에는 이들이 돌아갈 서버까지 고려해야 했는데, k8s로 인해 많은 문제가 자동으로 해결되었다 (물론, 완전히 사라진 것은 아니다). 반면, 그 아래의 플랫폼 팀에서는 위의 서비스에 대해서 깊게 알지 않고도, 서버의 메트릭 등을 활용하여 전체 시스템의 안정에 집중할 수 있다.
대부분의 k8s는 데이터 센터보다 훨씬 작기 때문에 클러스터의 크기가 무한히 확장 가능하다고 생각해도 괜찮은 경우가 많다. 하지만, 기반의 데이터 센터들을 운영해야 하는 AWS, Azure, GCP 등은 어떻게 유한한 자원을 무한처럼 보이면서 영업 마진을 지킬지 고민해야 한다 (대규모 시스템에서 비용 효율성은 가장 중요한 고려 조건 중 하나다1). 이들의 규모에서, 어떤 서버들을 더 사야 할지, 어떤 데이터 센터를 더 지어야 할지, 그리고 이들을 어떻게 네트워크로 연결할지 등은 몇십조 원 단위의 고민이 된다. (클라우드가 훨씬 작던 2018년 기준 구글이 인프라에만 일 년에 13조 원 정도 썼다고 한다2).
이 문제는 컴퓨터의 근간이 다양해지면서 (<개발 업계의 거시 흐름>에서 다룬 heterogeneity) 더 복잡해진다. 예를 들어, 어떤 서비스들은 GPU나 Local SSD 같은 자원을 요구할 수 있는데, 모든 서버가 이들을 구비하기는 너무 비싸고, 몇몇 서버들만 이들을 갖추게 된다. 이 상황에서 적어도 다음의 두 가지 문제를 풀어야 한다3.
- 실시간 스케줄링 (Online scheduling): 요청이 들어왔을 때 이들을 어떤 서버에 배치할 것인지 빠르게 결정해야 한다. Local SSD를 요청하지 않는 프로세스라도 다른 서버에 자리가 없다면 Local SSD가 있는 서버에 배치하는 것이 프로세스를 완전히 거절하는 것보다 좋을 수 있다.
- 오프라인 플래닝 (Offline planning): 계속 커가는 클라우드를 효율적으로 성장시키기 위해, 어떤 종류의 서버들을 더 구비할지 결정해야 한다. 데이터 센터를 직접 운영하지 않더라도, 그 아래의 클라우드 제공자에게 받아오는 (provisioning) 속도가 느리다면 비슷한 문제가 있을 것이다.
두 문제는 다음과 같은 꽤 합리적으로 보이는 기본 알고리즘을 생각할 수 있다.
- 스케줄링: 가능한 서버 중 가장 저렴한 서버에 새로운 프로세스를 배치한다.
- 플래닝: 가장 부하가 많은 서버를 더 구매한다.
부가적으로, 이 두 문제의 중간에는 이미 돌고 있는 서비스들을 어떤 다른 서버로 옮길지에 대한 문제도 추가될 수 있다. 예를 들어, 서버에 문제가 있다면, 서비스를 꺼버리는 것보다 다른 서버로 옮겨주는 것이 더 좋은 선택일지 모른다. Live migration 같은 기능은 이 움직임을 부드럽게 해줄 수 있는데 (다양한 제약이 있긴 하지만), 이 같은 기술을 활용하면 다음 스케줄링을 위해서 이미 돌고 있는 서비스들을 옮기는 것이 가능할 수도 있다 (잘 정의해둔 SLO가 이럴 때도 유용하다).
기본 알고리즘의 문제점과 개선 🔗
문제를 단순화하기 위해, 하나의 서버는 하나의 요청만 처리할 수 있다고 하자.
그리고 요청의 종류는 3가지밖에 안 되고 (A: CPU와 메모리만 요청, B: SSD도
요청, C: GPU도 요청. GPU와 SSD를 동시에 요청하는 경우는 없음), 서버들의 종류도
3가지라고 생각해 보자 (이들도 A, B, C 타입이라고 부르자). A 타입의 요청은 A, B,
C 서버 아무 데서나 돌아갈 수 있지만, B 타입은 B에서만, C 타입은 C에서만 돌 수
있다.
- A, B, C 타입의 서버가 각각 3대씩 있다고 하자.
- 상황 1: A 타입의 요청만 6개가 왔다면, 이들은 9대의 서버 중 아무 6대나 사용할 수 있다. 처음 3개는 A로, 그다음 3개는 비싼 GPU를 아끼기 위해서 B로 배치될 것이다. A와 B 타입의 서버들은 모두 100% 사용하게 된다.
- 결과 1: 이 상황만 보면, B에 있는 A 타입의 요청은 C로도 옮길 수 있기 때문에, A, B, C 타입 모두 추가로 3개의 요청을 더 받을 수 있다 (동시에 받을 수 있다는 것은 아니다).
- 문제점 1: 서버들의 부하만 가지고 다음 구매할 서버를 결정하면, 100% 사용되고 있는 B를 쓸데없이 많이 사게 된다. 아무도 B를 원하지 않는데도 말이다. 사용자 패턴이 유지된다면, A 타입의 서버만 더 구매하는 것이 효율적일 것이다.
- 상황 2: 시간이 지나면서 A 타입의 요청이 3개 사라지고, 그만큼 B 타입의 요청이 들어왔다고 하자.
- 결과 2: 여전히 A와 B 타입의 서버들만 100% 사용하고 있지만, B 타입은 더 이상 추가로 받을 수 없다.
- 문제점 2: 어떤 종류의 요청이 거절될 위기에 있는지 서버들의 부하만으로는 판단하기 어렵다. 이런 위험은 미리 감지할 수 있다면 다양한 대비를 준비할 수 있지만, 사용자의 요청이 들어온 몇 초 안에 해결하기는 더 어렵다.
이때, 위에서 나온 이분 그래프와 최대 이분 매칭을 활용하면 꽤 효율적이고 확장이 가능한 구조를 만들 수 있다. 왼쪽은 사용자들의 요청, 오른쪽은 서버들이라고 하면 다음과 같이 나타낼 수 있다.
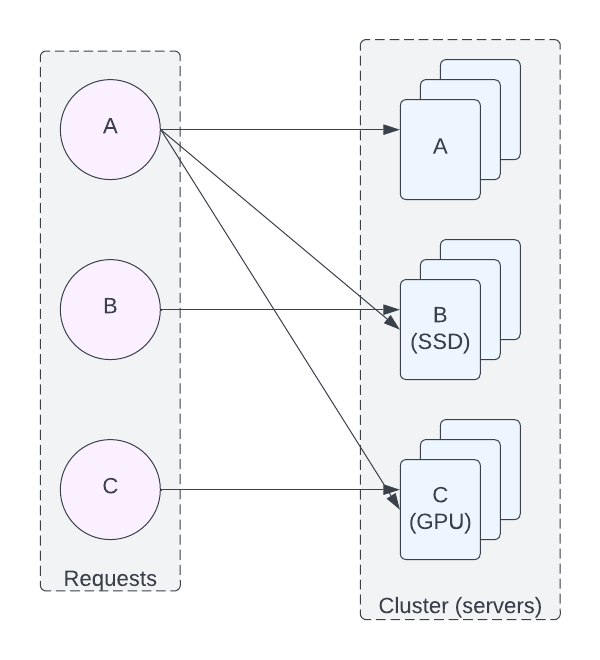
상황 1에서 A는 9개의 사용 가능한 서버가 있고, 더 추가할 수 있는 요청은 3이니, 67% 사용 중이라고 표시할 수 있다. 반면 B와 C는 0% 사용 중이다 (비록, B 서버들이 100% 사용 중 임에도 말이다). 상황 2에서는 A와 C의 사용률은 유지되지만, B는 100% 사용 중이 된다. 보통의 서버 모니터링으로는 보이지 않던 문제가 이분 그래프로 확연하게 드러나는 것이다. 그리고 이 수치는 그래프가 더 복잡해지면 더욱 강력한 도구가 될 수 있다. 그리고 최대 매칭을 위한 알고리즘은 (Ford-Fulkerson) 이들을 효과적으로 계산하게 해준다.
아쉽지만, 위의 그림에 비해 실제 시스템은 더 지저분해지곤 하며, 대회에서 볼 수 있는 최적값보다는 근사치라는 표현이 더 맞을 것 같다. 하나의 서버에 수많은 프로세스가 작동할 수도 있고, 하나의 서비스는 여러 rack에 배치하는 것을 선호할 수도 있는 등 (rack 단위의 문제가 생겼을 때 충격을 줄이기 위해), 다양한 고려 사안들이 있기 때문이다. 복잡성의 비용도 무시할 수 없어서, 대부분의 경우는 유형 별로 다른 k8s 클러스터를 운영하거나 제약 사항들을 (taint 같은) 적극 활용하는 것이 더 합리적일 것 같다는 시시한 결론으로 글을 마무리해 본다. ∎
-
The Datacenter as a Computer는 현재의 대규모 시스템과 클라우드 컴퓨팅에 지대한 영향을 준 책인데, 여기서 비용이 얼마나 강조되는지 볼 수 있다. ↩︎
-
Google Cloud Blog: Expanding our global infrastructure with new regions and subsea cables ↩︎