❄️ 2019년 글 커리어 눈 굴리기에서 약간 이어집니다.
높아진 금리가 실물 경제에 충격을 주고 있다는 뉴스가 2023년을 장식했다. 회사들은 거시 상황이 안 좋아져서 직원들을 내보낸다 하고, 국제 갈등 속에 물가도 많이 올라갔다. 이처럼 눈에 보이지 않는 거대한 흐름이 우리의 소소한 일상에 큰 영향을 준다. 개인의 최선의 선택은 그 흐름을 이해하고, 파도타기를 하듯 유리하게 활용하는 것이 되겠다.
서퍼가 파도를 잡고 거기에 머물러있으면 그는 아주 멀리 갈 수 있다. 하지만 파도에서 내리는 순간 얕은 물 속에 나자빠지게 된다. – 찰리 멍거 (워렌 버핏의 오랜 사업 파트너)
When a surfer gets up and catches the wave and just stays there, he can go a long, long time. But if he gets off the wave, he becomes mired in shallows. – Charlie Munger
그리고, 거시 경제만큼이나 강력한 파도는 기술의 흐름에서 온다. 금리가 높을 때 대출을 더 조심해야 하듯, 기술의 파도를 잘 타는 것은 커리어를 굴려 나가는데 중요한 원동력이다. 예를 들어, 컴퓨팅 성능이 1980년대에 가파르게 좋아지지 않았다면 애플과 마소가 이 정도로 성장하지 못했을 것이다. 2010년대의 클라우드 컴퓨팅은 Stripe, Pinterest, Airbnb 같은 기업들의 성공을 가능하게 했다. 이들을 가능하게 한 혁신은 엄청나게 새로운 것이 출현했다기보다는, 가격 대비 성능이 커지거나, 필요한 자본 지출이 (CAPEX) 줄어들면서 가능했다는 점을 주목할 만하다.

이 글에서는 2020년대에 영향을 주고 있는 두 큰 파도와 그로 인해 파생된 또 하나의 파도에 대해 정리해 본다.
- 무어의 법칙의 종말과 이질적인 공급: 컴퓨터는 어떻게 변하고 있나
- 더욱 거대해져 가는 수요: 컴퓨터 사용은 어떻게 변하고 있나
- 복잡성과 솔루션 전쟁: 중간의 소프트웨어는 어떻게 변하고 있나
그리고 사업자나 투자자뿐 아니라 미미한 개인에게도 도움이 될 수 있다는 것을 보여주기 위해, 실제 월급 개발자로서 이런 흐름을 이용한 사례들도 간단하게 공유해보려 한다.
1. 무어의 법칙의 종말과 이질적인 공급 🔗
컴퓨터가 지금처럼 인류에게 지대한 영향을 줄 수 있던 근본적인 이유는 지난 50년간 성능이 비현실적으로 발전했기 때문이다. 1965년 인텔의 창업자 무어가 “예측”한 대로 컴퓨터 칩의 성능은 기하급수적으로 성장했고, 집마다 개인용 컴퓨터를 두던 시대를 넘어서 개개인이 모바일 컴퓨터를 들고 다니는 세상을 가능하게 했다. 개발자들은 부담 없이 파이썬같이 인간 친화적인 언어들을 사용하며 엄청난 생산성 향상을 누릴 수 있었다. 이 강력한 성장이 무려 50년을 지속해서 “법칙”처럼 느껴지지만, 전혀 보장된 것이 아니었고, 아래에서 보이듯이 2015년 무렵부터는 연 3% 성장만 보인다.1
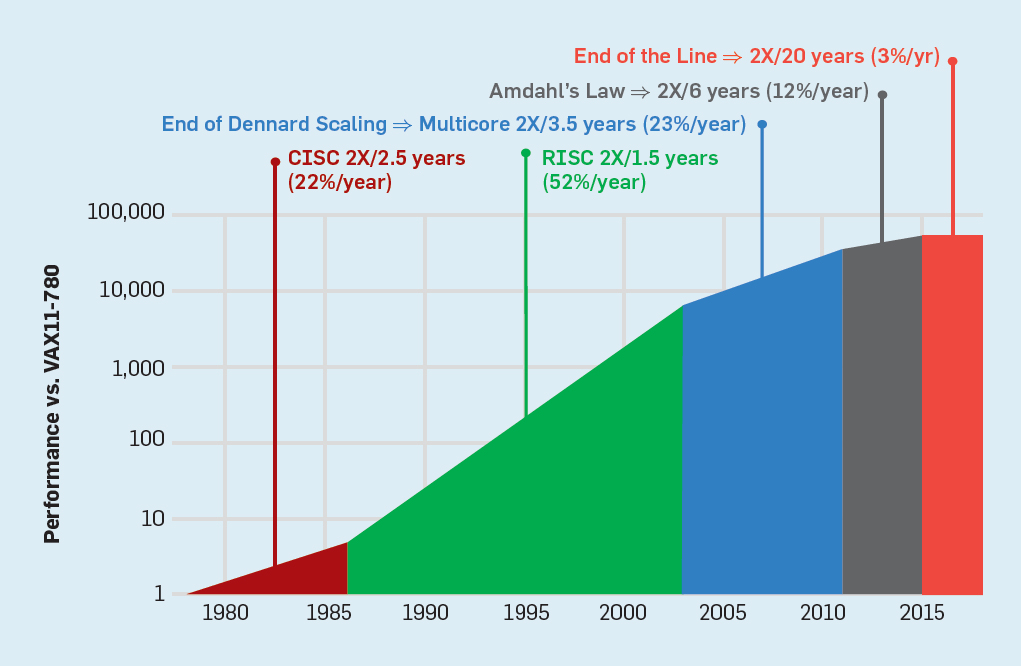
하드웨어 성능 발전이 완전히 멈춘 것은 아니다. 다만, 모든 스프트웨어를 자동으로 향상하던 오래된 힘이 약해진 것이다. 그리고 그 힘의 공백을 메우기 위해서 CPU 같은 범용 컴퓨팅이 아니라 더 한정적인 일을 훨씬 잘 해내는 특수 목적 하드웨어의 범람이 자연스럽게 시작되었다. 엔비디아의 GPU는 물론이고, 구글의 TPU, 유튜브의 Argos, 그리고 퓨리오사 같은 스타트업들은 모두 좋은 예다. 범용 CPU 내에서도 기존의 독보적인 Intel x86가 아닌 Arm기반으로 훨씬 가성비가 좋은 AWS Graviton이나 GCP Tau 같은 옵션도 생겼으니, 호랑이 없는 굴에서 모두가 여우라고 주장하는 판국이다.
이 거대한 파도는 빅테크를 먼저 덮쳤지만2, 좋든 싫든 모두에게 영향을 줄 것이다. 게다가 컴퓨팅뿐 아니라 네트워크와 스토리지도 견줄 만큼 파격적인 변화를 만들고 있고, 그 위의 클라우드 컴퓨팅은 또 다른 기회를 제공하고 있다. 예를 들어, 스노플레이크는 클라우드를 활용하여 스토리지와 컴퓨팅을 분리한 데이터 플랫폼을 내놓았는데, 이처럼 컴퓨팅, 네트워크, 스토리지를 기존과 다른 방식으로 엮는 다양한 사례는 앞으로도 계속 나올 것이다. 결과적으로, “컴퓨터"의 정의가 모든 계층에서 변화하고 있고, 그들 간의 경계는 희미해져 가고 있으며, 이전의 x86기반의 동질적인 (homogeneous) 시스템이 아닌 이질적인 (heterogeneous) 세상을 받아들여야 할 것이다.
2. 더욱 거대해져 가는 수요 🔗
위에서 말한 공급의 문제가 수요의 감소와 이어졌다면 큰 문제는 아니었을 것이다 (개발 직군의 가치는 많이 낮아졌겠지만). 하지만 우리는 그야말로 소프트웨어로의 전환의 시대를 살고 있다. 인터넷 사용자는 20년 전에 10억 명이 안 되던 것이 이제는 53억 명이라 하고3, 다들 스마트폰을 들고 다니며, 매 순간이 수많은 사진과 영상으로 변환된다. 이런 데이터를 잘 활용하여 가치를 주는 것은 모두에게 기회이자 위기다.
모든 회사는 이제 소프트웨어 회사다. – 사탸 나델라 (마이크로소프트 CEO)
Every company is now a software company. – Satya Nadella
단순히 양만 늘어나는 것이 아니라 데이터를 이해하는 기술도 엄청나게 발전하고 있다. 2012년 그림에 표범이 있는지를 이해하는 수준에서 (AlexNet), 2016년에는 바둑 챔피언을 이기고 (AlphaGo), 2022년에는 사람과 구분하기 힘든 수준의 창작과 문제해결 능력을 보여준다 (GPT-4). 그리고 이런 고성능을 만들기 위한 컴퓨팅 수요는 위의 무어의 법칙보다도 빠르게 커지고 있다4. ChatGPT를 비롯한 거대 언어 모델들(LLM)이 최근에 엄청난 관심을 받지만, 여전히 광고 같은 추천 시스템도 매우 중요한 수요다5.

데이터의 양, 그들을 처리하기 위한 컴퓨팅 크기뿐 아니라 데이터가 흐르는 속도도 빨라졌다. 예를 들어서 사용자가 어떤 상품에 관심을 보이면, 서비스들은 그 정보를 바로 활용하여 사용자의 흥미를 더 끌고 싶어 한다. 과거에는 데이터 분석 자체가 생소했고, 있더라도 사용자의 행동이 발생한 시간과 분석하는 시간의 큰 차이가 있었지만, 이제는 모든 것이 즉각적으로 일어나기를 기대한다. 남는 컴퓨팅 자원을 효율적으로 활용할 수 있던 오프라인 데이터 분석에 비해 이런 실시간 처리는 수요를 더욱 늘린다.
3. 복잡성과 솔루션 전쟁 🔗
위의 두 파도는 양옆으로 소프트웨어를 강하게 압박하며 새로운 파도를 만들어 내고 있다. 퍼블릭 클라우드에서 시총 전 세계 5위 안에 드는 세 공룡이 치열하게 경쟁하는 것은 물론이고 (AWS, Azure, GCP), 그 주위에는 아래에서처럼 수많은 SaaS 회사가 고군분투한다6. 2025년이 되어서야 퍼블릭 클라우드에 쓰는 돈이 전체 IT의 절반을 넘는다고 하니7, 이 춘추전국시대는 꽤 오래 지속될 것으로 보인다.

이 혼란의 근본적인 이유는 위 파도들로 인해서 소프트웨어가 해결해야 할 문제가 본질적으로 더 어려워졌기 때문이다 (essential complexity8). 업계는 소프트웨어의 단위를 더 작게 만들고 (microservice), 데이터 중점적인 구조를 도입하며 (data architecture), 이런 일들을 담당할 조직을 꾸리면서 (platform engineering) 대응하고 있지만, 이 부분이 획기적으로 쉬워질 것 같지는 않다.
-
컴퓨팅 (microservice): 기존에는 서버가 프로세스 하나와 데이터베이스 정도로 이뤄졌다면 (monolith), 이제는 이들이 작은 단위로 쪼개지고 있다. 서버가 다뤄야 할 로직이 복잡해지기도 했지만, 각각의 로직이 다른 하드웨어를 사용해야만 하는 경우도 늘고 있기 때문이다 (예: 머신러닝 추론은 GPU를 이용). 이런 업계의 공통적인 수요로 인해 마이크로서비스를 운영하는 전반적인 기술이 빠르게 발전하고 있다. 서비스를 배포하고 (container, serverless), 운영하고 (k8s), 모니터링하는 (observability) 생태계가 지난 10년간 눈에 띄게 성숙해졌다. 더불어서 이들을 제품에 효율적으로 활용하는 모범 사례들도 자리를 많이 잡았다 (CD / CI, IaC, loose coupling).
-
데이터 (data architecture): 사용자는 서비스를 단방향으로 소비하던 관계였고, 여전히 그 뼈대는 중요하다. 예를 들어, 아마존은 판매자들이 미리 올려둔 제품들을 잘 보여줘야 한다. 하지만 그 주위로 흐르는 데이터도 매우 중요해졌다. 예를 들어, 사용자가 바나나와 다이어트 책을 샀다면, 소형 믹서기를 추천하는 것이 구매를 촉진할 수 있다. 장바구니에 담았다가 취소한 제품은 할인 광고의 효과가 더 좋을 것이다. 이런 개인화가 제품 품질에 큰 영향을 주기 시작했고, 자연스럽게 사용자의 다양한 행동들을 기록, 분석, 활용하면서 사생활은 보호하는 솔루션들도 활발하게 발전하고 있다 (Spark, Kafka, Flink, Snowflake, data catalog). 결과적으로, 정적이던 데이터가 훨씬 역동적으로 변하고 있으며, 이들을 머신러닝에 효과적으로 활용하는 전략도 중요해지고 있다 (feature store, vector database, data mesh, RAG, MLflow).
-
조직 (platform engineering): 위 두 변화는 어느 정도 필연적이지만, 전체적인 조율 없이는 복잡도만 급증하고 실속은 없기 쉽다. 자연스럽게, 기업들은 다양한 이름으로 이 변화를 만들어갈 팀들을 도입했다 (DevOps, Platform teams)9. 이들은 전략적으로 파도를 타면서 회사에 필요한 능력을 지속적이고 효율적으로 도입하는 임무가 있다 — 머신러닝이 중요한 화두라서 ML Platform을 따로 두는 경우도 흔하다. 아름다운 이상에 비해 현실은 어려움이 산적하다. 본질적인 복잡도를 단순한 추상화로 풀어내기 어렵기 때문에 이 복잡도는 밖으로 새어나갈 수밖에 없다. 이에 다른 팀들은 잘되던 시스템이 불필요하게 어려워졌다고 생각할 수도 있다. 결국 조직 하나 도입한다고 회사가 효율적으로 바뀔 수는 없고 (8에서 말한 no silver bullet의 연장선), 협력적인 문화, 리더십, 개발 역량이 함께 어울려 돌아가야 한다.
위 기업들을 둘러싸고 요동치는 주식시장에서 볼 수 있듯이 5년 뒤의 모습이 어떨지는 누구도 확신할 수 없다. 이 흐름을 단순히 두 파도의 잔물결로 보는 것이 아니라 새로운 파도로 보는 이유는, 이에 따라 전반적인 소프트웨어 업계의 템포가 훨씬 빨라졌기 때문이다. 사용자들의 기대치는 높아졌고, 소프트웨어가 비즈니스에 미치는 영향력도 커졌으니, 어떻게 더 빠르게 이 복잡성을 다스리면서 가치를 전달할지가 개인과 기업의 핵심 역량으로 보인다.
빠른 제품 개발 속도는 수많은 문제를 해결한다. – 일론 머스크
A high production rate solves many ills. – Elon Musk
4. 개인적 사례들 🔗
판교, 실리콘밸리, 시애틀 등에서 10년을 넘게 지내면서 보니, 개개인의 역량 보다도 파도를 잘 잡는 것이 커리어를 만들어가는데 더 강력한 힘이 되는 경우가 많은 것 같다. 반면, 파도가 잘 치지 않는 곳에서는 개인적으로 뛰어난 분들도 능력 발휘하기가 쉽지 않아 보였다. 아무리 뛰어난 서퍼도 파도가 없으면 물장구밖에 칠 수 없는 것이다. 세 가지 소소한 개인적 사례를 적어본다.
4.a. 팀 선정 🔗
나는 k8s의 전신인 구글의 Borg 팀에서 2015년부터 2022년까지 만 6년 넘게 있었는데, 초반에는 부정적인 조언을 많이 받았다. 2003년에 시작된 레거시 프로젝트에서 새로운 일이 아니라 유지 보수만 하게 될 것이라는 합리적인 조언들이었다. 실제로 팀은 10명 남짓이었고, 최근 프로젝트들도 그다지 매력적이지 않았다 — 아마 그래서 팀에 들어가기는 더 쉬웠을 것이다.
하지만 구글이 위의 파도들을 헤쳐 나가기 위해서 Borg에서 해야 할 일들이 매우 많았고, 내가 나올 때는 100명짜리 팀이 되어있었다. 자연스럽게 나 같은 사람도 팀장을 해볼 수 있었고, 내가 입사한 무렵부터 있던 팀원들은 (원하는 경우) 대부분 구글에서 꽤 오르기 힘든 직급들까지 승진했다. 개개인이 열심히 하기도 했지만 강력한 파도 없이는 불가능했을 것이다.
4.b. 개발 팀 구축 🔗
개발 팀장의 조건에 관한 글에서도 언급 했다시피, 팀장이 되기 위한 가장 중요한 조건은 기회다. 5명짜리 팀이 3년 뒤에도 같은 메니저 아래에 5명으로 남아있으면 하는 일을 확장할 수는 있겠지만, 팀을 꾸릴 기회는 없을 수 밖에 없다. 물론, 성장을 위해서 팀장이 되는 것만이 유일한 길은 아니지만, 그 길은 막혀있는 것이 분명하다.
지금은 생각하기 힘들지만, 불과 4년전만 해도, 구글 클라우드는 VM 종류로 거의 N1 타입 하나만 제공했다 — E2가 2020년 3월에 추가되었고, 지금은 훨씬 다양하다. 결국 Borg도 클라우드의 이질적인 서버들을 관리해야 했고, 제대로 된 팀 없이는 산적한 프로젝트들을 모두 성공시킬 수 없다는 주장은 쉽게 받아들여졌다. Borg 특유의 문제들 때문에 외부 영입도 쉬운일이 아니었고, 자연스럽게 팀장으로 일할 기회가 생겼다.
4.c. 프로젝트 발굴 🔗
구글 다음에 들어간 쿼라는 내가 말단으로 입사하지 않은 첫 회사였는데, 회사의 규모가 작고 시니어가 적다 보니 괜찮은 프로젝트를 발굴하는 일부터 시작해야 했다. 이런 불확실성에도 불구하고, 위에서 적은 것처럼 ML Platform 영역에서 다양한 기회가 있을 것이라는 기대는 있었다.
이때, 위에서 정리한 파도들은 길을 찾는 데 큰 도움이 되었는데, 회사의 내부 사정을 세세하게 몰라도 연역적으로 (deduction) 구조적인 문제를 추론할 수 있었다. 예를 들어, 회사가 2009년에 시작한 만큼, 머신러닝을 운영하는 방식이 이질적인 공급에 잘 대응하면서 폭발적인 수요를 다룰 수 없을 것이라고 가정할 수 있었고, 비용이나 개발자 생산성에 문제가 되는 사례들을 쉽게 찾을 수 있었다 – 사례들로부터 귀납적으로 (induction) 문제를 찾을 수 있었겠지만, 조직은 관성이 있어서 문제가 있는 사례들이 쉽게 눈에 안 띌 수 있다.
물론, 문제 파악은 시작일뿐이고, 그다음 회사의 현실에 맞는 해결책을 수립하고, 실행해서 결과를 만들 수 없다면 의미가 없다. 하지만 좋은 프로젝트 없이 좋은 결과물을 만들기는 매우 어렵기에 프로젝트 발굴은 파도타기에 특히 중요하다. 다른 사람들이 좋은 프로젝트를 건네줄 수도 있지만, 스스로 의미 있는 프로젝트를 만드는 능력은 시니어 역할을 할수록 더 중요해지는 것 같다. 결국 기업 역시 더 큰 시스템의 구성 요소이고, 개인과 마찬가지로 거시 흐름에 영향을 받기에, 큰 변화는 기회가 될 수 있다.
5. 마치며 🔗
이전 글에서 커리어를 복리로 굴려 나가는 구조에 대해 적어보았다면, 이번 글은 굴리는 동력에 대해서 적어보았다. 혼자 끙끙거리며 미는 것이 아니라 외부의 거대한 힘을 잘 활용했을 때 우리는 더 멀리 나아갈 수 있는 것이다. 인류가 존재하는 한, 앞으로도 다양한 파도가 생겼다가 없어질 것이고, 본인의 파도에 집중하면 다른 사람들과의 소모적인 비교도 줄일 수 있을 것 같다 – 우리는 모든 파도를 다 탈 수도, 탈 필요도 없다.
5년 전의 눈 굴리기가 장기적 관점을 보여줬다면, 파도타기는 단기적 관점에 더 괜찮은 비유 같다10. 길게 보면 눈덩이가 복리로 커진 것이지만, 단기적으로는 외부 요인과 본인의 상황에 따라 다른 전략과 힘조절이 필요하기 때문이다. 모든 성장이 가시적이지도 않기 때문에 눈 굴리기는 단기적으로는 너무 미화되 보이기도 한다. 예를 들어, 내가 파도가 잘 치지 않는 바다에 있다면 좋은 바다로 옮기는 위치 선정이 가장 중요할 것이다. 남들이 어떻게 잘 타는지 연구하고, 작은 파도들을 타면서 훈련하고, 내 스타일을 만들어가는 것도 유의미한 성장이다. 좋은 파도를 타고 있다면 한눈팔지 말고 현재를 즐기되 그 파도가 끝나가면 다음 파도로 넘어가는 것도 중요할 것이다. ∎
-
유튜브 영상: John Hennessy (전 스텐포드 총장이자 튜링상 수상자) – 우리가 알던 무어의 법칙은 끝났다. 그래프는 튜링상 강의 CACM 출처. ↩︎
-
유튜브 영상: Amin Vahdat (구글 인프라 부사장) – 어떻게 다음 세대의 컴퓨팅이 진화할 것인가. ↩︎
-
UN의 산하기간인 ITU에서 나온 정보를 Statista에서 시각화 ↩︎
-
아래 그래프는 EPOCH의 보고서에서 가져왔다. 이들은 2010년까지는 머신러닝의 컴퓨팅 수요가 무어의 법칙 정도의 속도로 발전했으나, 딥러닝의 시대가 열리면서 6개월에 두배씩 크기 시작했고, 거대 모델의 시대가 2015년쯤 열리면서 트렌드가 이어지고 있다고 보았다. ↩︎
-
구글의 TPUv4 논문에서 딥러닝 기반 추천 모델의 수요는 여전히 전체 TPUv4 사용량의 24%라고 설명했는데, 이는 3년전의 27%에서 크게 달라지지 않았음을 보여준다. ↩︎
-
Jamin Ball라는 VC가 운영하는 SaaS 관련 뉴스레터 Clouded Judgement 출처. 이 뒤에는 수많은 비상장 회사들도 있다. ↩︎
-
소프트웨어 개발론에 지대한 영향을 준 Fred Brooks (튜링상 수상자)는 복잡성을 본질적 (essential)과 우연적 (accidental)으로 나눠서 정리했는데, 본질적인 문제는 간단한 해결책이 없고, 업계가 발달하면서 대부분의 문제는 본질적이 되었다는 것이다. 자세한 내용은 No Silver Bullet라는 유명한 에세이에서 더 볼 수 있다. ↩︎ ↩︎
-
모든 존재는 입자이자 파동이기 때문에 둘 다 의미 있다고 생각 :) ↩︎